+48 453 250 842
+48 453 250 842 office@bitpeak.com
office@bitpeak.com


Data Vault 2.0 – data model
After the first part of the article series about Data Vault where I introduced the concept and the basicis of its architecture, I return to you with more in-depth look into data modeling. I will analyze concepts such as Business keys (BKEYs), hash keys (HKEYs), Hash diff (HDIF) and more!
Data Vault – technical columns
Business Key (BKEY)
In contrast to traditional data warehouses, Data Vault does not generate artificial keys on its own, nor does it use concepts such as sequences or key tables. Instead, it relies on a carefully selected attribute from the source system, known as the Business Key (BKEY). Ideally, the BKEY should not change over time and be the same across all source systems where the data is generated. While this may not always be possible, it greatly simplifies passive model integration. Furthermore, in the context of GDPR requirements, it is not advisable to choose business keys that contain sensitive data as it can be challenging to mask such data when exposing the data warehouse.
Examples of BKEYs may include the VAT invoice number, the accounting attachment number, or the account number. However, finding a suitable BKEY may not be an easy task. One best practice is to check how the business retrieves data from source systems and which values are used when entering data into the source system. Typically, these values, as they are known to the business, are good candidates for BKEYs. Often, the same data is processed in multiple source systems. For instance, in an organization with several systems for processing tax documents (invoices, receipts), natural document numbers (receipt/invoice numbers) may be used in some, while an artificial key (attachment number) may be used in others. In some cases, a sequential document number and an equivalent natural number are also used. In such situations, using an integration matrix can help identify the appropriate BKEY.
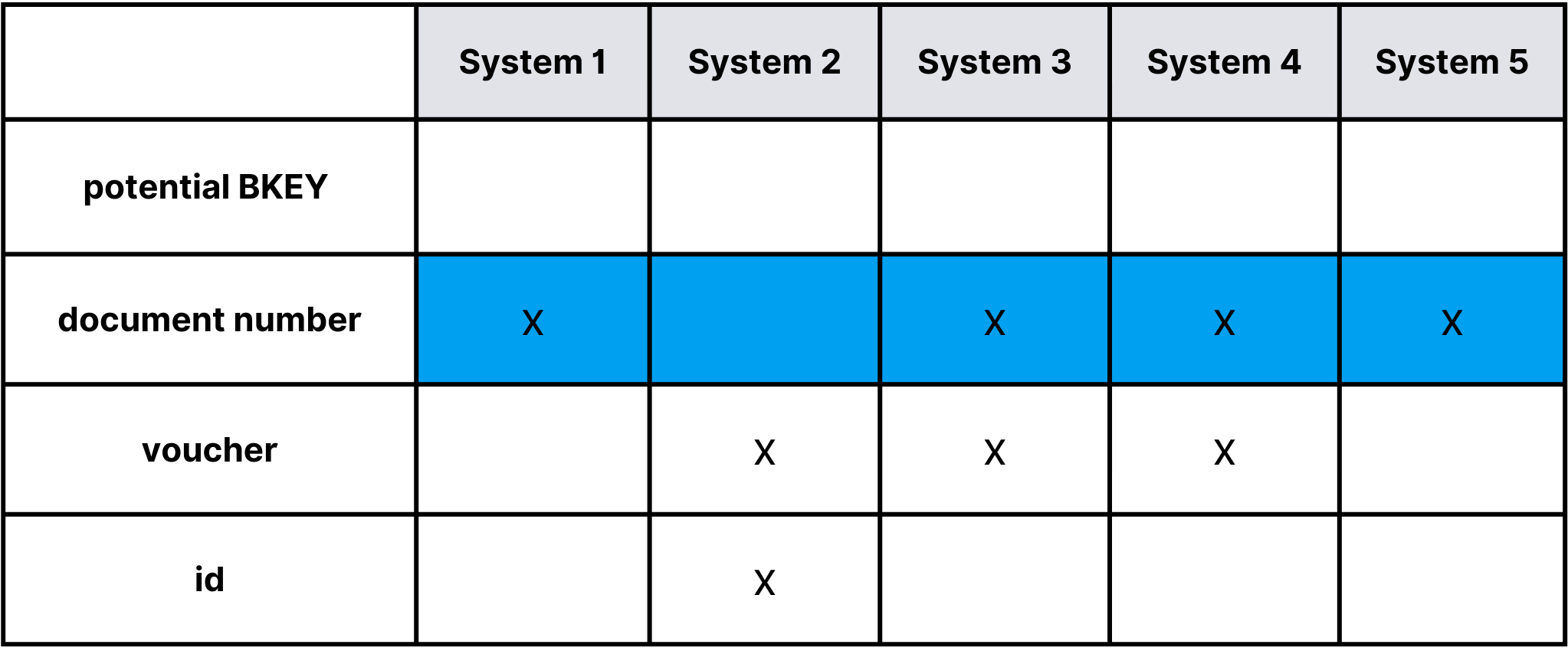
Matrix showcasing potential BKEY keys
As we can see from the matrix, there are several potential BKEY keys, but only the document number appears in the majority of the sources from which we retrieve document data. If we use a BKEY key based on the document number, the data in the Data Vault model will naturally integrate. However, what will we get for data from „System 2„? For this data, we need to design an appropriate same-as link (a Data Vault object) that will connect the same data. More on this in the later part of the article.
It is important that the same BKEY keys from different source systems are loaded in the same way. Even if we want to format such a key, for example, by adding a constant prefix, we should do it in the same way for data from all sources.
Hash key (HKEY)
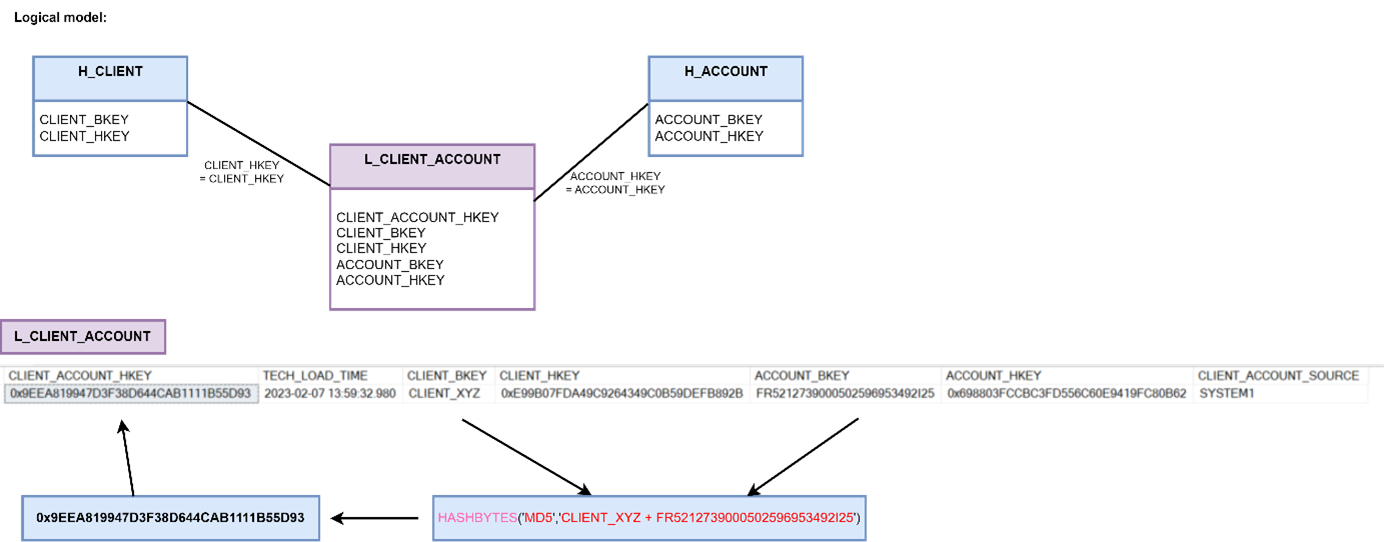
In the DV model, all joins are performed using a hash key. The hash key is the result of applying a hash function (such as MD5) to the BKEY value. The hash key is ideal for use as a distribution key for architectures with multiple data nodes and/or buckets. Through distribution, we can efficiently scale queries (insert and select) and limit data shuffling, as data with the same BKEY values are stored on the same node (having received the same HKEY).
 Example BKEY and HKEY:
Example BKEY and HKEY:
Hash diff (HDIF)
In Data Vault objects that store historical data (SCD2), HDIF represents the next versions of a record. HDIF is calculated by computing a hash value on all the meaningful columns in the table.
LoadTime
Date and hour of record loading.
DelFlag
Indication that a record has been deleted. It is important to note that in Data Vault 2.0 it is not recommended to use validity periods (valid from – valid to) to maintain historical records. As this requires costly update operations that are not efficient, especially for real-time data. In addition, for some Big Data technologies, update operations may not be available, which further complicates the implementation of validity periods. Instead, Data Vault recommends an insert-only architecture based on technical columns such as LoadTime and DelFlag to indicate when a record has been deleted.
Source
For Data Vault tables that receive data from multiple sources, the source column allows for additional partitioning (or sub-partitioning) to be established. Proper management of the physical structure of the table enables independent loading of data from multiple sources at the same time.
Different types of Data Vault objects have different sets of technical columns, which will be discussed further in the article.
Passive integration
In classic warehouses, there are often so-called key tables in which keys assigned to business objects on a one-off basis are stored. Loading processes read the key table and, based on this, assign artificial keys in the warehouse. There are also sequences based on which keys are assigned, and sometimes a GUID is used.
All these solutions require additional logic to be implemented so that the value of the keys can be assigned consistently in the warehouse model. Often, these additional algorithms also limit the scalability of the warehouse resource. Passive integration is the opposite of this approach. Passive integration involves calculating a key on the fly during a table feed based only on the business key. With a deterministic transformation (hash function on BKEY), we can do this consistently in any dimension, e.g:
- model dimension – the same BKEY in different warehouse objects will give us the same hkey so we can feed them independently and then combine them in any consistent way
- time dimension – feeding the same BKEY at different points in time will give us the same result. Records powered up a year ago and today will get the same HKEY. Clearing the data and feeding it again will also have no effect on the calculated values (unlike, for example, in the case of sequences)
- environment dimension – the same BKEY will have the same HKEY on different environments which facilitates testing and development.
The above is possible, but only if we choose the BKEY correctly, so the necessary effort should be made to make the choice optimal. We should consistently calculate it with the same algorithm for all HUB objects in the model. The exception can appear when we know that we have potential BKEYs in different formats in the source systems, but a simple transformation will make it consistent. It is important that this transformation is of the 'hard rule’ type.
For example:
In system 1 we have the key BKEY: „qwerty12345”
In system 2 we have the key BKEY: „QWERTY12345”
We know that business-wise they mean the same thing. In this case, we can apply a „hard rule” in the form of a LOWER or UPPER function to make the keys consistent.
Unfortunately, there are also situations where we have completely different BKEYs in different systems, for example:
In system 1 we have the key BKEY: „qwerty12345”
In system 2 we have the key BKEY: „7B9469F1-B181-400B-96F7-C0E8D3FB8EC0”
For such cases, we are forced to create so-called same-as links, which we will discuss later in this article.
Physical objects in Data Vault
Data Vault objects appear in the same form in both the RDV and BDV layers. The differences between them are only in the way the values in these objects are calculated (Hard rules and Soft rules). The objects of each layer should be distinguished at the level of naming convention and/or schema or database
RDV
- HUB
- LINK
- SATELLITE
-
- Standard
- Effectiveness
- Multiactivity
BDV
- Business HUB
- Business LINK
- Business SATELLITE
-
- Standard
- Effectiveness
- Multiactivity
HUB type objects
Hubs in the Data Vault warehouse are objects around which a grid of other related objects (satellites and links) is created. A Hub is a 'bag’ for business keys. A Hub cannot contain technical keys that the business does not understand, the keys must be unique. Examples of HUBs could be: customer, bill, document, employee, product, payment, etc.
We feed the Hubs with keys (BKEY) from the source systems, one BKEY can represent data from multiple source systems. We can use some rules to calculate BKEY but only those that meet the hard rules (usually UPPER, LOWER, TRIM). We never delete data from the HUB, if a record has disappeared from the source systems then its key should remain in the HUB. Even if the data is loaded into the hub in error, we do not need to delete unnecessary keys.
 Example HUB structure, description of technical columns one chapter earlier.
Example HUB structure, description of technical columns one chapter earlier.
Satellite type objects
It stores business attributes. We can have satellites with history (SCD2) or without history (SCD0/SCD1). We create a new satellite when we want to separate some group of attributes. We can do this for a number of reasons:
a) we want to store data of the same business importance (e.g. address data) in one place
b) we want to separate fast-changing attributes into a separate satellite. Fast-changing attributes are those that change frequently causing duplication of records in the satellite. Examples of such attributes could be e.g. interest rate, account balance, accrued interest, etc.
c) we want to segregate attributes with sensitive data for which we will apply restrictive permission policies or GDPR rules.
d) we want to add a new system to the warehouse and create a new satellite for it
e) others that for some reason will be optimal for us
Data Vault is very flexible in this respect. However, be sure to document the model well.
 Example of a satellite with data recorded in SCD2 mode:
Example of a satellite with data recorded in SCD2 mode:
Multiactive satellite – a specific type of a satellite where the key is not only BKEY but also a special multiactivity determinant (one of the substantive attributes). An example of such a satellite is a satellite storing address data where the multiactivity determinant is the type of address (correspondence, main, residential).
We have one BKEY (e.g. login in the application) and several addresses. We can successfully replace the multiactivity satellite with a regular one by adding a multiactivity determinant column to the hashkey calculation. My experience shows that it is better to limit the use of multiactivity satellites for reasons of model readability and reading efficiency.
 Example of a multiactivity satellite with data recorded in SCD2 mode
Example of a multiactivity satellite with data recorded in SCD2 mode
Link type objects
Link objects come in several versions:
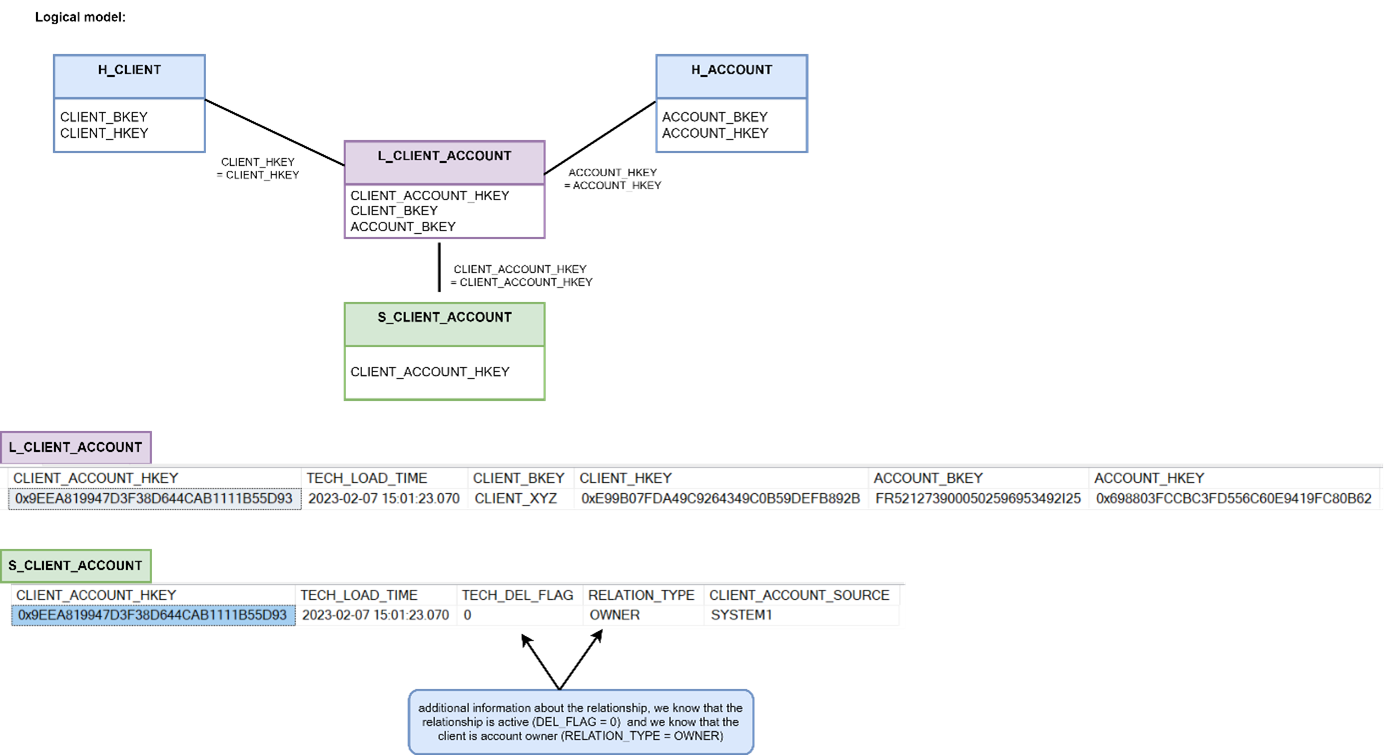
Relational link – represents relationships between two or more objects which can be powered by complex business logic. Relationships must be unique – this is achieved by generating a unique hash for the relationship which is calculated from the hashes of the records it links. A link does not contain business columns (the exception is an nonhistorized link).
If we want to show history then we need to attach a satellite with a timeline to the link (effectivity satellite). The performance satellite can also contain additional business columns describing relationships.
Hierarchical link – used to model parent-child relationships (e.g. organisational structure) This type of link can of course also store history. To achieve that – just add an efficiency satellite to the link.
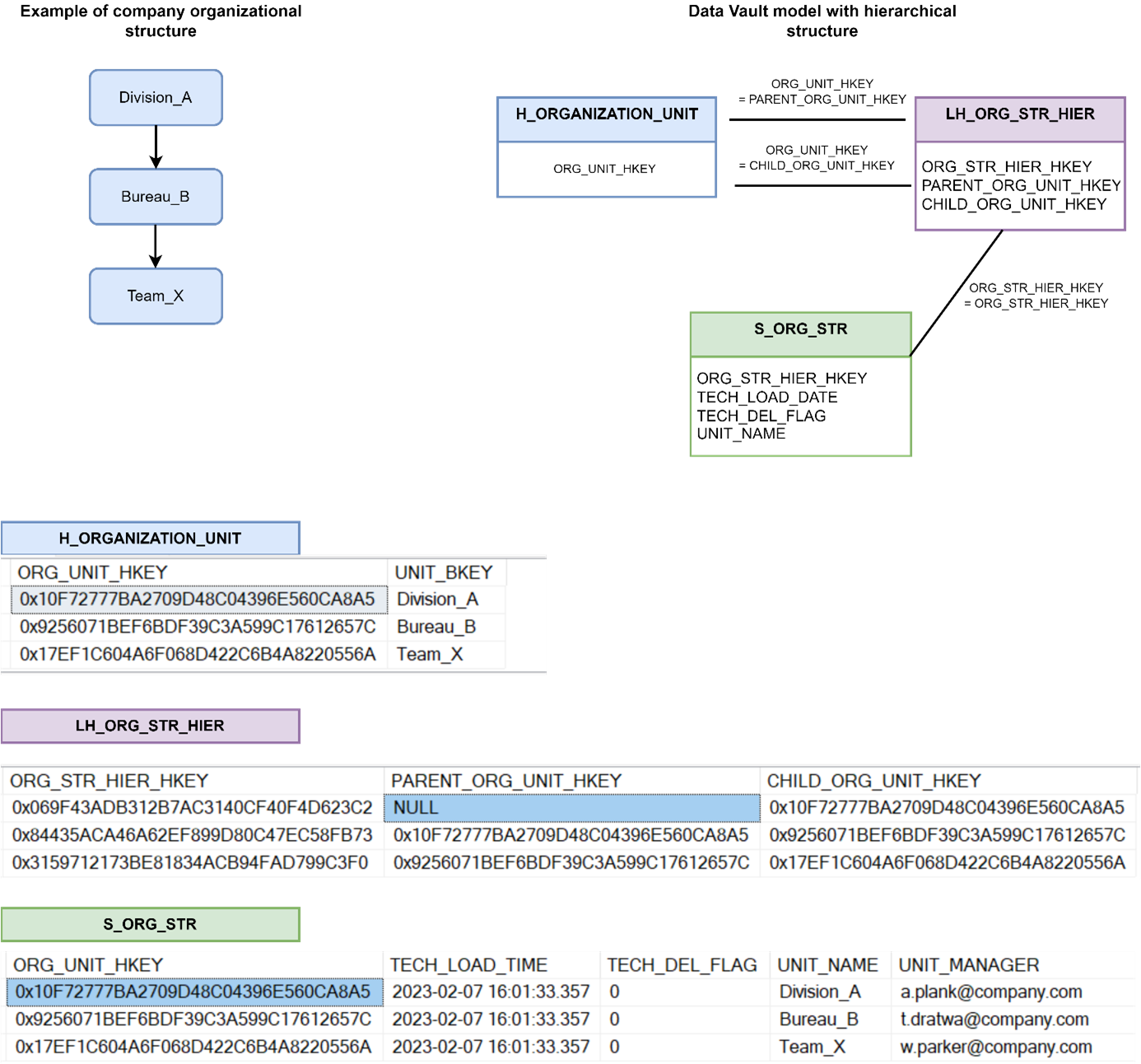 An example of an organisational structure in the Data Vault model using a hierarchical link and an efficiency satellite:
An example of an organisational structure in the Data Vault model using a hierarchical link and an efficiency satellite:
Non-historicised link (also known as transactional links) – a link that may contain business attributes within it, or may be associated with a satellite which has these attributes. The important thing is that it stores information about events that have occurred and will never be changed (like a classic fact table). Examples of such data are: system logs, invoice postings that can only be changed/withdrawn with another posting (storno accounting), etc.
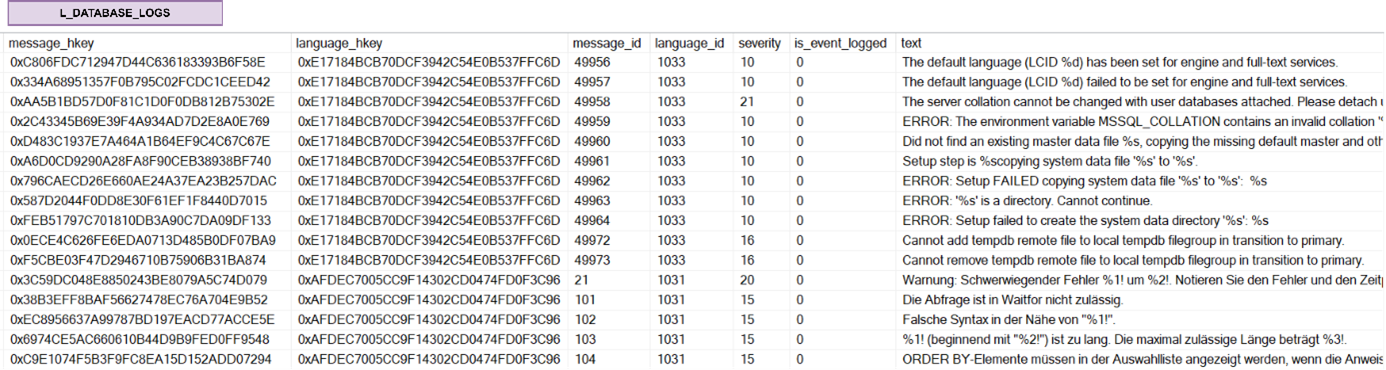 and example of a Non-historicised link
and example of a Non-historicised link
Link same as – allows you to tag different BKEY keys in the HUB table that essentially mean the same thing business-wise. I have mentioned this in previous chapters when describing the selection of the optimal BKEY. It is very important to note that this link only combines BKEY keys that business mean the same thing, we do not use the same as to register relationships other than mutually explicit relationships. We can use advanced algorithms to calculate often non-obvious links and record the results of the calculation in the link.
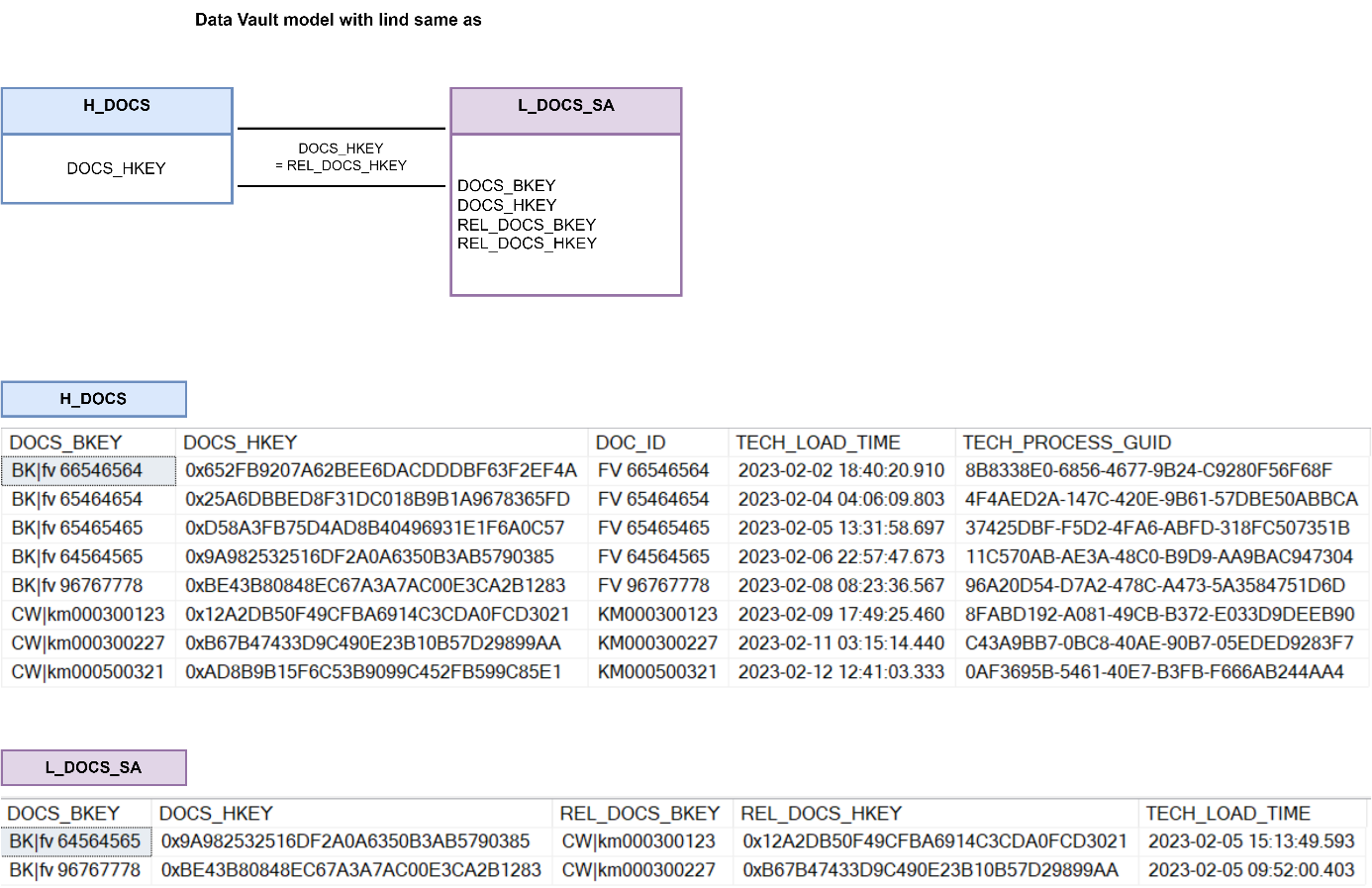 Examples of “same as” link
Examples of “same as” link
Links such as „same as” can be used in situations when we want to indicate often non-obvious business relationships, but also in very mundane situations. For example, when two systems have completely different business keys that represent the same thing, or when a key changes over time and we want to capture and record that change.
PIT facility – The Data Vault model is fragmented, as we have many subject satellites correlated to HUBs. Queries in the warehouse often involve several HUBs and satellites correlated with them. Selecting data from a specific point in time can be a challenge for the database. To improve read performance we use Point In Time (PIT) objects. A PIT table is something like a business index.
The important point is that we create PITs for specific business requirements. We define a set of source data (hubs, satellites), combine selected tables of hubs, links and satellites in such an arrangement as the business expects, e.g. for a selected moment in time (selected timeline or other business parameter). These are objects that we can reload and clean at any time, depending on the requirements of the recipient and the limitations of the hardware/system platform. The PIT is constructed from keys that refer to the hub and satellites so that we can retrieve data from these objects with a simple „inner join„.
A PIT facility can also refer to links instead of HUBs and satellites attached to a link.
BRIDGE object – works similarly to the PIT object with the difference being that it does not speed up access to data on a specific date but speeds up reading of a specific HKEY. Like PIT objects, BRIDGE objects are also created for the specific requirements of the data recipient. Bridge objects contain keys from multiple links and associated HUBs.
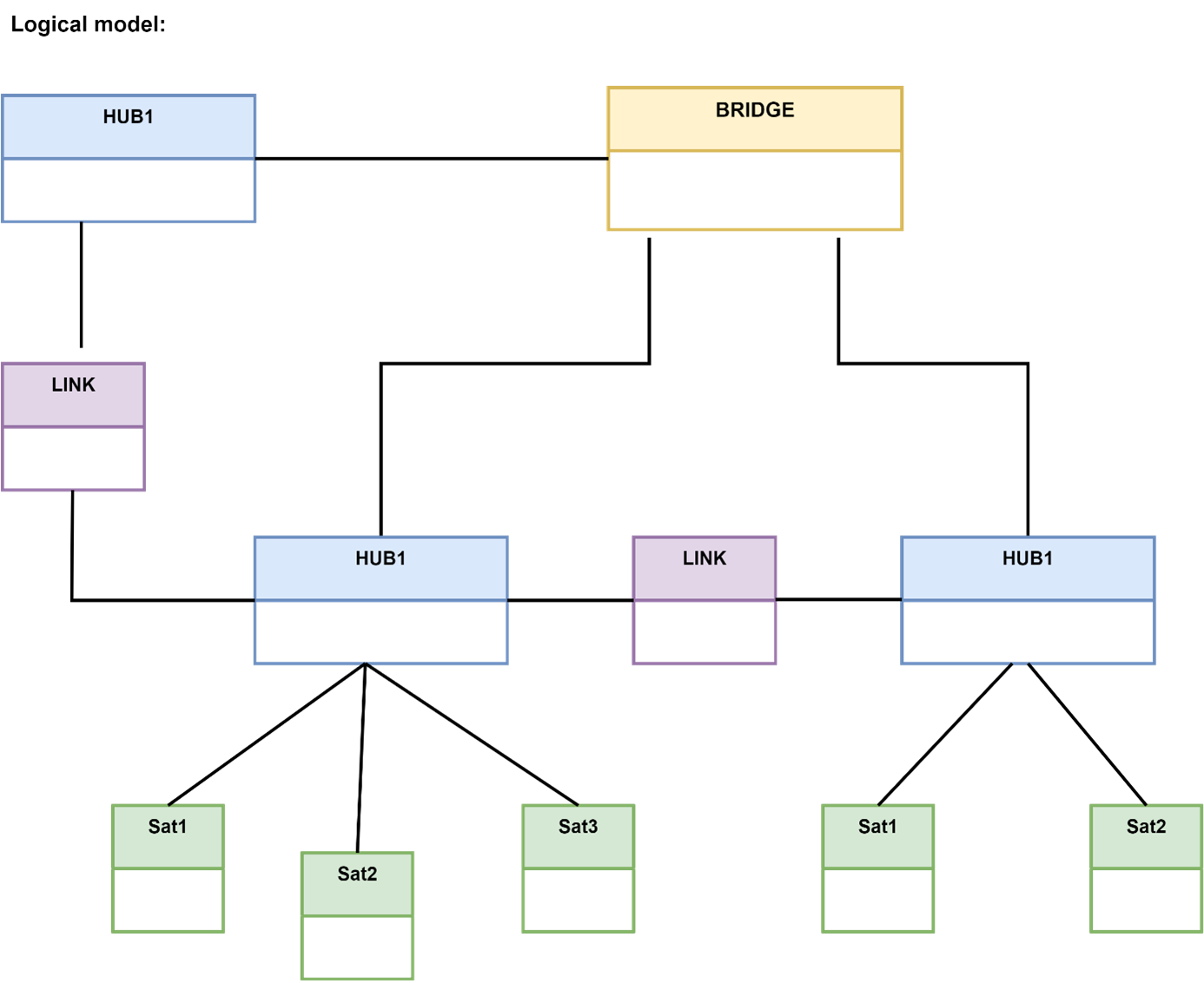
The raw Data Vault model is not an easy model to use, it is difficult to navigate without documentation and therefore should not be made widely available to end users. The PIT as well as the Bridge objects help the end-user to read the DataVault data efficiently but it is important to remember that they are not a replacement for the Information Delivery (Data Mart) layers. They should be considered more as a bridge and/or optimisation object to produce higher layers. Of course, creating a PIT/Bridge object also costs money, so this optimisation method is used where there are many potential customers.
This concludes the second part of our series of articles about Data Vault and its implementation. Next week, you will be able to read about naming convention. Additionally, you will be able to find the summary of the information provided so far! To make sure you will not miss the next part of the series, be sure to follow us on our social media linked below. And if you have additional questions about data – let’s talk about it!
All content in this blog is created exclusively by technical experts specializing in Data Consulting, Data Insight, Data Engineering, and Data Science. Our aim is purely educational, providing valuable insights without marketing intent.