
 (+48) 508 425 378
(+48) 508 425 378 office@bitpeak.pl
office@bitpeak.pl


A brief overview of the importance of data quality
What is data quality?
Data quality refers to the condition or state of data in terms of its accuracy, consistency, completeness, reliability, and relevance. High-quality data is essential for making informed decisions, driving analytics, and developing effective strategies in various fields, including business, healthcare, and scientific research. There are six main dimensions of data quality:
- Accuracy: Data should accurately represent real-world situations and be verifiable through a reliable source.
- Completeness: This factor gauges the data’s capacity to provide all necessary values without omissions.
- Consistency: As data travels through networks and applications, it should maintain uniformity, preventing conflicts between identical values stored in different locations.
- Validity: Data collection should adhere to specific business rules and parameters, ensuring that the information conforms to appropriate formats and falls within the correct range.
- Uniqueness: This aspect ensures that there is no duplication or overlap of values across data sets, with data cleansing and deduplication helping to improve uniqueness scores.
- Timeliness: Data should be up-to-date and accessible when needed, with real-time updates ensuring its prompt availability.
Maintaining high quality of data often involves data profiling, data cleansing, validation, and monitoring, as well as establishing proper data governance and management practices to maintain high-quality data over time.
Why is data quality important?
Data collection is widely acknowledged as essential for comprehending a company’s operations, identifying its vulnerabilities and areas for improvement, understanding consumer needs, discovering new avenues for expansion, enhancing service quality, and evaluating and managing risks. In the data lifecycle, it is crucial to maintain the quality of data, which involves ensuring that the data is precise, dependable, and meets the needs of stakeholders. Having data that is of high quality and reliable enables organizations to make informed decisions confidently.
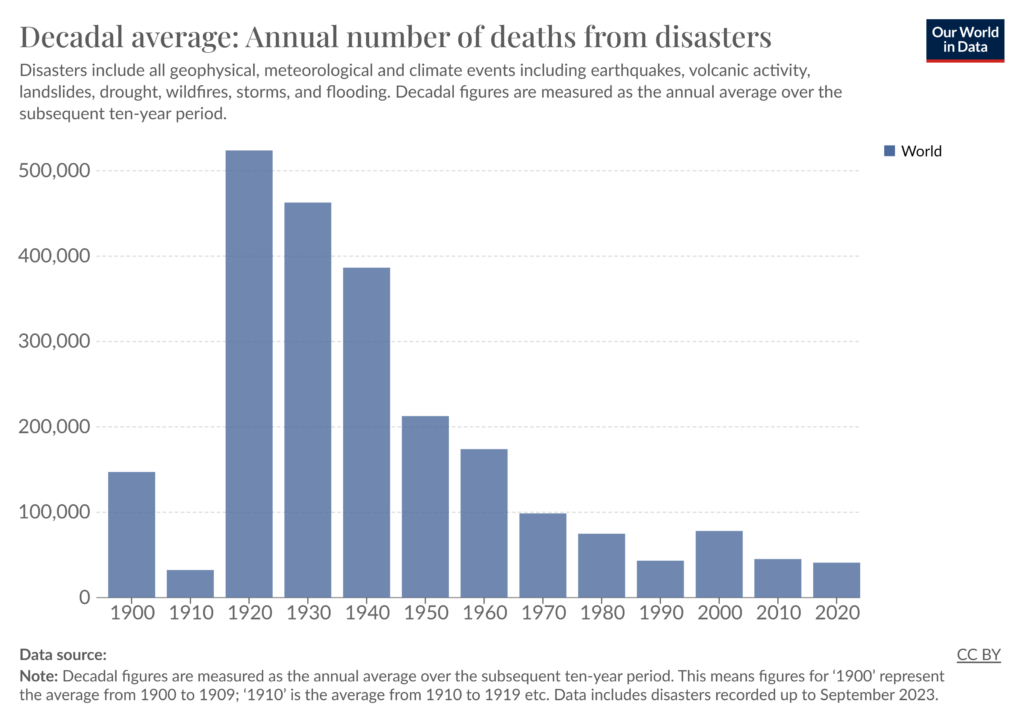
Figure 1. Average annual number of deaths from disasters. Source “Our World in Data”.
While this example may seem quite dramatic, the value of quality management with respect to data systems is directly transferable to all kinds of businesses and organizations. Poor data quality can negatively impact the timeliness of data consumption and decision-making. This in turn can cause reduced revenue, missed opportunities, decreased consumer satisfaction, unnecessary costs, and more.
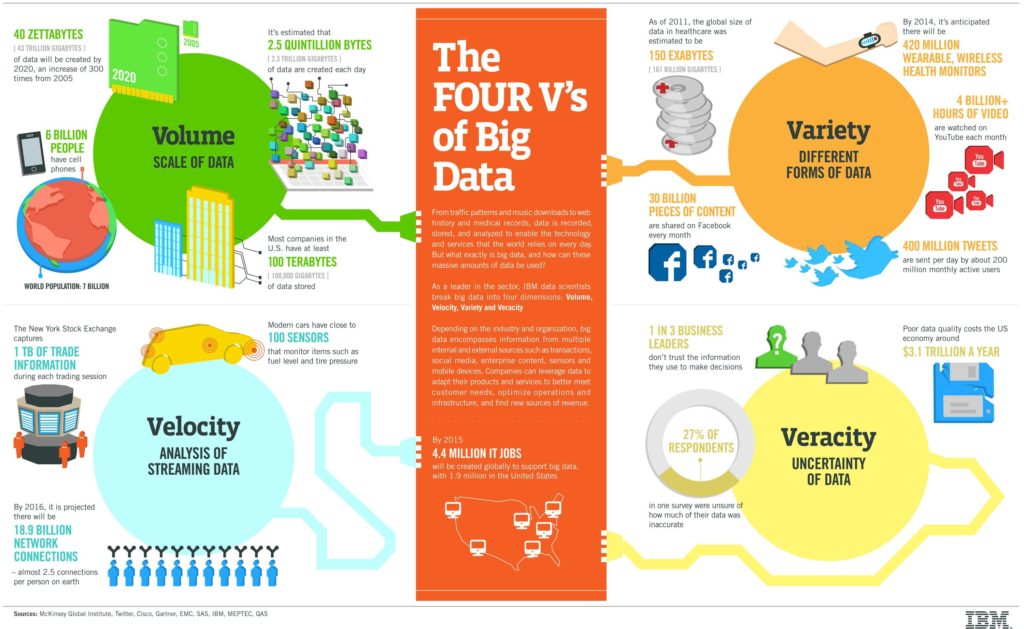 Figure 2. IBM’s infographic on “The Four V’s of Big Data”
Figure 2. IBM’s infographic on “The Four V’s of Big Data”
According to an IBM around $3.1 trillion of the USA’s GDP is lost due to bad data, and 1 in 3 business leaders doesn’t trust their own data. In a 2016 survey, it was shown that data scientists spend 60% of their time cleaning and organizing data. This process could and should be streamlined. It ought to be an inherent part of the system. This is where dbt might help.
What is dbt and how can it help with quality management tasks?
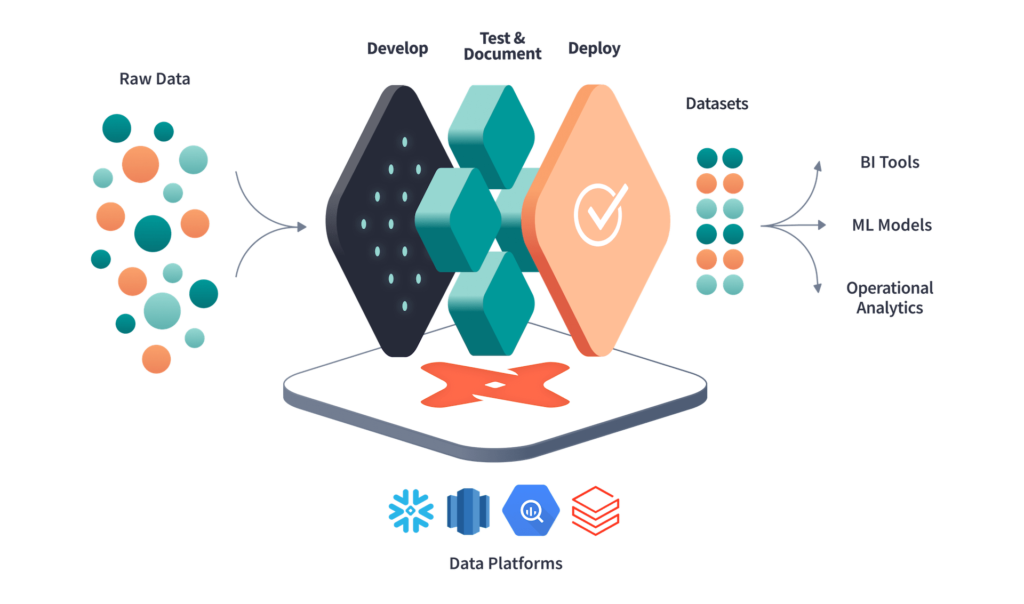 Figure 3. dbt workflow overview
Figure 3. dbt workflow overview
Data Build Tool, otherwise known as dbt, is an open-source command-line tool that helps organizations transform and analyze their data. Using the dbt workflow allows users to modularize and centralize analytics code while providing data teams with the safety nets typical of software engineering workflows. To allow users to modularize their models and tests, dbt uses SQL in conjunction with Jinja. Jinja is a templating language, which dbt uses to turn your dbt project into a programming environment for SQL, giving you tools that aren’t normally available with SQL alone. Examples of what Jinja provides are:
- Control structures such as if statements and for loops
- Using environment variables in the dbt project for production deployments
- The ability to change how the project is built based on the type of current environment (development, production, etc.)
- The ability to operate on the results of one query to generate another query as if they were functions accepting and returning parameters
- The ability to abstract snippets of SQL into reusable “macros,” which are analogues to functions in most programming languages
- The great advantage of using dbt is that it enables collaboration on data models while providing a way to version control, test, and document them before deploying them to production with monitoring and visibility.
In the context of quality management, dbt can help with data profiling, validation, and quality checks. It also provides an easy and semi-automatic way to document the data models. Lastly, through dbt, one can document the outcomes of some quality management activities, collecting the results and thus supplying more data on which the stakeholders can act.
Reusable tests
In dbt tests are created as SELECT queries that aim to extract incorrect rows from tables and views. These queries are stored in the SQL files and can be categorized into two types: singular tests and generic tests. Singular tests are used to test a particular table or a set of tables. They can’t be easily reused but might be useful anyway. Generic tests are highly reusable, serving basically as test macros. For a test to be generic, it has to accept the model and column names as parameters. Additionally, generics can accept an infinite number of parameters as long as those parameters are strings, Booleans, integers, or lists of the mentioned types. This means that tests are reusable and can be constantly improved. Additionally, all tests can be tagged, which then allows running only tests with a specific tag if we want to.
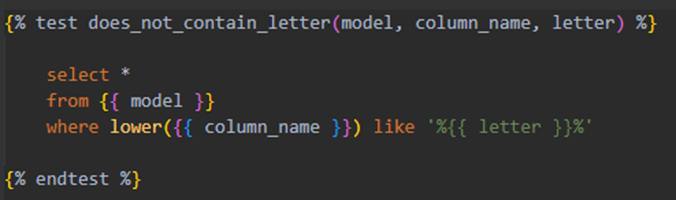
Figure 4. Example generic tests checking if a column contains a specified letter
Documenting test results
It is possible to store test results in distinct tables, with each table holding the results for a single test. Whenever a test is run, its results overwrite the previous ones. But you can run queries on those tables and store the results by using dbt’s hooks. Hooks are macros that execute at the end of each run (there are other modes, but for now, this one is sufficient). By using the „on-run-end” hook, you can, for instance, loop through the executed tests, obtain row counts from each of them, and insert this information into a separate table with a timestamp. This data can now be easily utilized to generate a graph or table, providing actionable insights to stakeholders.
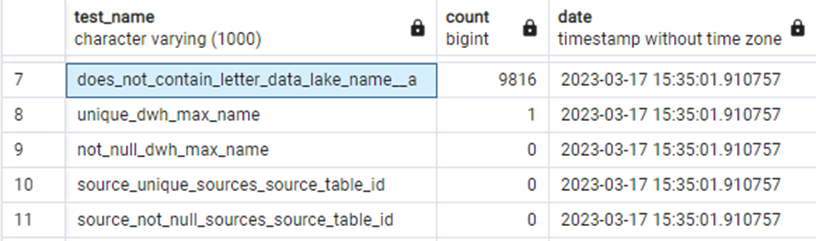 Figure 5. Example of a test summary created through a macro
Figure 5. Example of a test summary created through a macro
Documenting data pipelines and tests
dbt has a self-documenting feature that allows for easy comprehension of the yaml configuration file by running the „dbt docs serve” command. The documentation can be accessed from a web browser, and it covers generic tests, models, snapshots, and all other dbt objects. In addition, users can include additional details in the YAML configuration, such as column names, column and model descriptions, owner information, and contact information. Users can also designate a model’s maturity or indicate if the source contains personally identifiable information. As previously noted, documentation of processes is a critical aspect of quality management. With dbt, this process is made easy, leaving no excuse for omitting it.
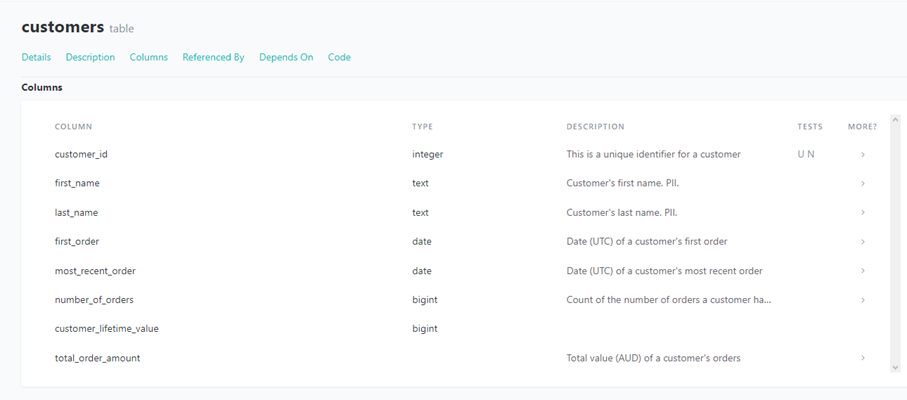 Figure 6. Excerpt from dbt’s documentation of a table
Figure 6. Excerpt from dbt’s documentation of a table
Generated documentation can also be used to track data lineage. By examining an object, you can observe all of its dependencies as well as the other objects that reference it. This data can be visualized in the form of a „lineage graph.” Lineage graphs are directed acyclic graphs that show a model’s or source’s entire lineage within a visual frame. This greatly helps in recognizing inefficiencies or possible issues further in the process when attempting to integrate changes.
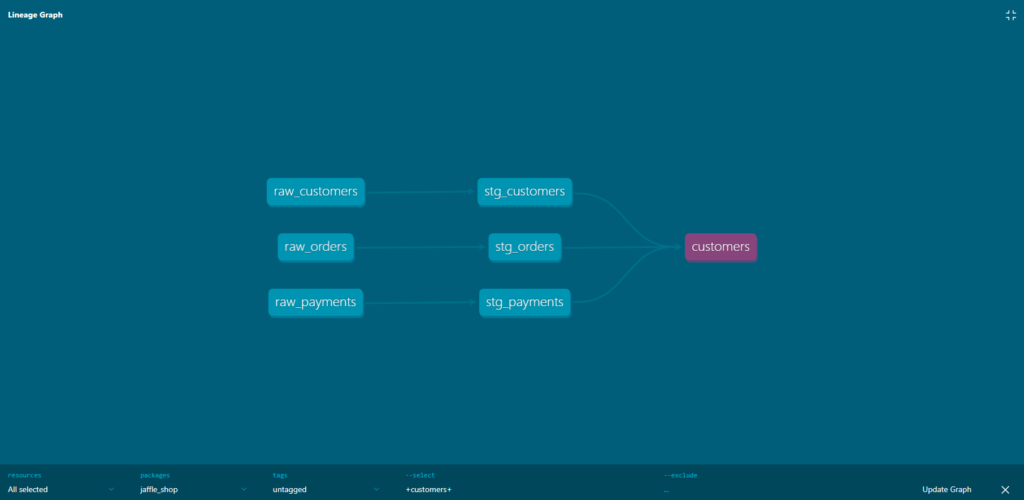 Figure 7. Example of dbt’s lineage graph
Figure 7. Example of dbt’s lineage graph
Version control
Version control is a great technique that allows for tracking the history of changes and reverting mistakes. Thanks to version control systems (VCS) like Git, developers are free to collaborate and experiment using branches, knowing that their changes won’t break the currently working system. dbt can be easily version controlled because it uses yaml and SQL files for everything. All models, tests, macros, snapshots, and other dbt objects can be version controlled. This is one of the safety nets in the software developer workflow that dbt provides. Thanks to VCS, you can rest assured that code is not lost due to hardware failure, human error, or other unforeseen circumstances.
Summing up
The importance of data quality for data analytics and engineering cannot be overstated. Ensuring data accuracy, completeness, consistency and validity is critical to making informed decisions based on reliable data, creating measurable value for the organization. Maintaining high data quality involves processes such as data profiling, validation, quality checks, and documentation. Data Build Tool (dbt), an open-source command-line tool, used for data transformation and analysis, can also greatly help with those tasks. dbt can assist in creating reusable tests, documenting test results, documenting data pipelines, tracking data lineage, and maintaining version control of everything inside a dbt project. By using dbt, organizations can streamline their quality management processes, enabling collaboration on data models while ensuring that data fulfills even the highest standards.
All content in this blog is created exclusively by technical experts specializing in Data Consulting, Data Insight, Data Engineering, and Data Science. Our aim is purely educational, providing valuable insights without marketing intent.







