+48 453 250 842
+48 453 250 842 office@bitpeak.com
office@bitpeak.com


Introduction
In the process of building RAGs (Retrieval Augmented Generation), chunking is one of the initial stages, and it significantly influences the future performance of the entire system. The appropriate selection of a chunking method can greatly improve the quality of the RAG. There are many chunking methods available, which were described in the previous article. In this one, I focus on comparing them using metrics offered by LlamaIndex and visualizing chunks created by individual algorithms on diverse test texts.
The LlamaIndex metrics are used to compare RAGs constructed based on chunks generated by various chunking methods, and the chunks themselves will also be compared in various aspects. Additionally, I propose a new chunking method that addresses the issues of currently available chunking methods.
Problems of available chunking methods
Conventional chunking methods sometimes create chunks in a way that leads to loss of context. For instance, they might split a sentence in half or separate two text fragments that should belong together within a single chunk. This can result in fragmented information and hinder the understanding of the overall message.
Currently available semantic chunking methods encounter obstacles that the present implementation cannot overcome. The main challenge lies in segments that are not semantically similar to the surrounding text but are highly relevant to it. Texts containing mathematical formulas, code/algorithm blocks, or quotes are often erroneously chunked due to the presence of these elements in the text, as the embeddings of these fragments are significantly different.
Classical semantic chunking typically results in the creation of several chunks (including usually several very short ones, such as individual mathematical formulas) instead of one larger chunk that would better describe the given fragment. This occurs because the currently created chunk will be „terminated” when it encounters the first fragment that is semantically different from chunk’s content.
Semantic double-pass merging
The issues described above led to the development of the chunking algorithm called “semantic double-pass merging”. Its first part resembles classical semantic chunking (based on mathematical measures such as percentile/standard deviation). What sets it apart is an additional second pass that allows merging of previously created chunks into larger and hence more content-rich chunks. During the second pass, the algorithm looks „ahead” two chunks. If the examined chunk has sufficient cosine similarity with the second next chunk it sees, it will merge all three chunks (the current chunk and the two following ones), even if the similarity between the examined chunk and the next one is low (it could be textually dissimilar but still semantically relevant). This is particularly useful when the text contains mathematical formulas, code/algorithm block, or quotes that may „confuse” the classical semantic chunking algorithm, which only checks similarities between neighboring sentences.
Algorithm
The first part (and the first pass) of the algorithm is a classical semantic chunking method: perform the following steps until there are no more sentences available:
- Split the text into sentences.
- Calculate cosine similarity (c.s.) for the first two available sentences.
- If the cosine similarity value is above the initial_threshold, then merge those sentences into one chunk. Else the first sentence becomes a standalone chunk and return to step 2 with the second sentence and the subsequent one.
- If reached the maximum allowable length, stop its growth and proceed to step 2 with the two following sentences.
- Calculate cosine similarity between the last two sentences of the existing chunk and the next sentence.
- If the cosine similarity value is above the appending_threshold, add the next sentence to the existing chunk and return to step 4.
- Finish the current chunk and return to step 2.
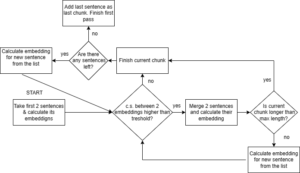
Figure 1 – Visualization of the first pass of “semantic double-pass merging” method.
To address scenarios where individual sentences, such as quotations or mathematical formulas embedded within coherent text, pose challenges during semantic chunking, a secondary pass of semantic chunking is conducted.
- Take the first two available chunks.
- Calculate cosine similarity between those chunks.
- If the value exceeds the merging_threshold, then two chunks are merged, ensuring that the length of these chunks does not exceed the maximum allowable length. Then take the next available chunk and return to step 2. If the length does exceed the limit then finish the current chunk and return to step one with second chunk used in that comparison and next available chunk. Elsewhere move to step 4.
- Take next available chunk and calculate cosine similarity between first examined chunk and the new (third in that examination) one.
- If the value exceeds the merging_threshold, then three chunks are merged, ensuring that the length of these chunks does not exceed the maximum allowable length. Then take the next available chunk and return to step 2. If the length does exceed the limit then finish the current chunk and return to step one with second and third chunk used in that comparison.
If the cosine similarity from the fifth step exceeds the merging threshold, it indicates that the middle-examined chunk was a „snippet” (possibly a quote/mathematical formula/pseudocode) with different embedding values from its surroundings, but still a semantically significant part of the text. This transition ensures that the resulting chunks will be semantically similar and will not be interrupted at inappropriate points, thus preventing information loss.
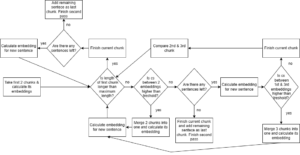
Figure 2 – Visualization of the second pass of “semantic double-pass merging” method.
Parameters
Thresholds in the algorithm control the grouping of sentences into chunks (in the first pass) and chunks into larger chunks (in the second pass). Here’s a brief overview of the three thresholds:
- initial_threshold: Specifies the similarity needed for initial sentences to form a new chunk. A higher value creates more focused chunks but may result in smaller chunks.
- appending_threshold: Determines the minimum similarity required for adding sentences to an existing chunk. A higher value promotes cohesive chunks but may result in fewer sentences being added.
- merging_threshold: Sets the similarity level for merging chunks. Higher value consolidates related chunks but risks merging unrelated ones.
For optimal performance, set the appending_threshold and merging_threshold relatively high to ensure cohesive and relevant chunks, while keeping the initial_threshold slightly lower to capture a broader range of semantic relationships. Adjust these thresholds based on text characteristics and desired chunking outcomes. Additionally, examples should be added: monothematic text should have higher merging_threshold and appending_threshold in order to differentiate chunks, even if the text is highly related, and to avoid classifying the entire text as a single chunk.
Comparative analysis
The comparative analysis of key chunking methods were conducted in the following environment:
- Python 3.10.12
- nltk 3.8.1
- spaCy 3.7.4 with embeddings model: en_core_web_md
- LangChain 0.1.11
For the purpose of comparing chunking algorithms, we used LangChain’s SpacyTextSplitter for token-based chunking and sent_tokenize function provided by nltk for sentence-based chunking. After using sent_tokenize, the chunks were created by grouping them according to a predetermined number of sentences. The proposition-based chunking was performed using various OpenAI GPT language models. For semantic chunking with percentile breakpoint LangChain implementation was used.
Case #1: Simple short text
The first test involved assessing how specific models perform (or not) with a simple example where topic change is very distinct. However, the description of each of the three topics consisted of a different number of sentences. Parameters for both token-based chunking and sentence-based chunking were set so that the first topic is correctly classified.
To conduct the test, the following methods along with their respective parameters were used:
- Token-based chunking: LangChain’s CharacterTextSplitter using tiktoken
- Tokens in chunk: 80
- Tokenizer: cl100k_base
- Sentence-based chunking: 4 sentences per chunk
- Clustering with k-means: sklearn’s KMeans:
- Number of clusters: 3
- Semantic chunking percentile-based: LangChain implementation of SemanticChunker with percentile breakpoint with values for breakpoint 50/60/70/80/90
- Semantic chunking double-pass merging:
- initial_threshold: 0.7
- appending_threshold: 0.8
- merging_treshold: 0.7
- spaCy model: en_core_web_md

Figure 3 – Token-based chunking.

Figure 4 – Sentence-based chunking.
Both token-based and sentence-based chunking encounter the same issue: they fail to detect when the text changes its topic. This can be detrimental for RAGs when „mixed” chunks arise, containing information about completely different topics but connected because these pieces of information happened to occur one after the other. This may lead to erroneous responses generated by the RAG.

Figure 5 – Chunking with k-means clustering.
The above image excellently illustrates why clustering methods should not be used for chunking. This method loses the order of information. It’s evident here that information from different topics intertwines within different chunks, causing the RAG using this chunking method to contain false information, consequently leading to erroneous responses. This method is definitely discouraged.

Figure 6 – LangChain’s semantic chunking with breakpoint_type set as percentile (breakpoint = 60).
Typical semantic chunking struggles to perfectly segment the given example. Various values of the breakpoint parameter were tried, yet none achieved perfect chunking.

Figure 7 – Semantic chunking with double-pass mergingafter first pass of the algorithm.
The primary goal of the first pass of the double-pass algorithm is to accurately identify differences between topics and only connect the most obvious sentences together. In the above visualization, it is evident that no mini-chunk contains information from different topics.

Figure 8 – Semantic chunking with double-pass merging after second pass of the algorithm.
The second pass of the double-pass algorithm correctly combines previously formed mini-chunks into final chunks that represent individual topics. As seen in the above example, the double-pass merging algorithm handled this simple example exceptionally well.
Case #2: Scientific short text
The next test was to examine how a text containing pseudocode would be divided. The embeddings of pseudocode snippets would significantly differ from the embeddings of text snippets that cut through them. Ultimately, the text and its description should be combined into one chunk to maintain coherence. For this purpose, a fragment of text from Wikipedia about the Euclidean algorithm was chosen. In this comparison, the focus was on juxtaposing semantic chunking methods, namely classical semantic chunking, double-pass, and propositions-based chunking:
- Semantic chunking percentile-based: LangChain implementation of SemanticChunker with percentile breakpoint set to 60/99/100
- Proposition-based chunking using gpt-4
- Semantic chunking double-pass merging:
- initial_threshold: 0.6
- appending_threshold: 0.7
- merging_threshold: 0.6
- spaCy model: en_core_web_md
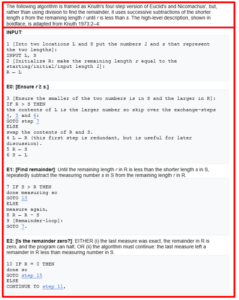
Figure 9 – Semantic chunking with percentile breakpoint set at 99.
Semantic chunking using percentiles was unable to comprehend the text as a single chunk. The entirety of the sample text was merged into one chunk only when the breakpoint value was set to the maximum value of 100 (which merges all sentences into one chunk).

Figure 10 – Semantic chunking with percentile breakpoint set at 60.
Semantic chunking using percentiles with a breakpoint set to 60, which allows for distinguishing between sentences on different topics, struggles with this example. It cuts the algorithm in the middle of a step, resulting in chunks containing fragments of information.

Figure 11 – Semantic double-pass merging chunking.
The double-pass merging algorithm performed admirably, interpreting the entire text as a thematically coherent chunk.
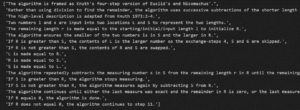
Figure 12 – Propositions created by propositions-based chunking.

Figure 13 – Chunk created by propositions-based chunking.
The proposition-based chunking method first creates a list of short sentences describing simple facts and then constructs specific chunks from them. In this case, the method successfully created one chunk, correctly identifying that the topic is uniform.
Case #3: Long text
To assess how different chunking methods perform on longer text, the well-known 'PaulGrahamEssayDataset’ available through LlamaIndex was utilized. Subsequently, simple RAGs were constructed based on the created chunks. Their performance was evaluated using the RagEvaluatorPack provided by LlamaIndex. For each RAG, the following metrics were calculated based on 44 questions provided by LlamaIndex datasets:
- Correctness: This evaluator depends on reference answer to be provided, in addition to the query string and response string. It outputs a score between 1 and 5, where 1 is the worst and 5 is the best, along with a reasoning for the score. Passing is defined as a score greater than or equal to the given threshold. More information here.
- Relevancy: Measures if the response and source nodes match the query. This metric is tricky: it performs best when the chunks are relatively short (and, of course, correct), achieving the highest scores. It’s worth keeping this in mind when applying methods that may produce longer chunks (such as semantic chunking methods), as they may result in lower scores. The language model checks the relationship between source nodes and response with the query, and then a fraction is calculated to indicate what portion of questions passed the test. The range of this metric is between 0 and 1.
- Faithfulness: Measures if the response from a query engine matches any source nodes which is useful for measuring if the response is hallucinated. If the model determines that the question (query), context, and answer are related, then the question is counted as 1, and a fraction is calculated to represent what portion of test questions passed the test. The range of values for faithfulness is from 0 to 1.
- Semantic similarity: Evaluate the quality of a question answering system by comparing the similarity between embeddings of the generated answer and the reference answer. The value of this metric ranges between 0 and 1. Read more about this method here.
More detailed definitions of faithfulness and relevancy metrics are described in this article.
To conduct this test, the following models were created:
- Token-based chunking: LangChain’s CharacterTextSplitter using tiktoken
- Tokens in chunk: 80
- Tokenizer: cl100k_base
- Sentence based: chunk size is set to 4 sentences,
- Semantic percentile-based: Langchain’s SemanticChunker with percentile_breakpoint set to 0.65,
- Semantic double-pass merging:
- initial_threshold: 0.7
- appending_treshold: 0.6,
- merging_treshold: 0.6,
- spaCy model: en_core_web_md
- Propositions-based: using gpt-3.5-turbo/gpt-4-turbo/gpt-4 in order to create propositions and chunks. The code is based on the implementation proposed by Greg Kamradt.
For comparison purposes, the average time and costs of creating chunks (embeddings and LLM cost) were juxtaposed. The obtained chunks themselves were also compared. Their average length in characters and tokens was checked. Additionally, the total number of tokens obtained after tokenizing all chunks was counted. The cl100k_base tokenizer was used to calculate the total token count and the average number of tokens per chunk.
| Chunking method | Average chunking duration | Average chunk length [characters] |
Average chunk length [tokens] |
Total token count | Chunking cost [USD] |
| Token-based | 0.08 sec | 458 | 101 | 16 561 | <0.01 |
| Sentence-based | 0.02 sec | 395 | 88 | 16 562 | 0 |
| Semantic percentile-based | 8.3 sec | 284 | 63 | 16 571 | <0.01 |
| Semantic double-pass merging | 16.7 sec | 479 | 106 | 16 558 | 0 |
| Proposition-based using gpt-3.5-turbo | 9 min 58 sec | 65 | 14 | 2 457 | 0.29 |
| Proposition-based using gpt-4-turbo | 1 h 43 min 30 sec | 409 | 85 | 6 647 | 17.8 |
| Proposition-based using gpt-4 | 40 min 38 sec | 548 | 117 | 5 987 | 29.33 |
As we can see, classical chunking methods operate significantly faster than methods attempting to detect semantic differences. This is, of course, due to the higher computational complexity of semantic chunking algorithms. When looking at chunk length, we should focus on comparing two semantic methods used in the comparison. Both token-based and sentence-based methods have rigid settings regarding the length of created chunks, so comparing their results in terms of chunk length won’t be very useful. Chunks created by classical semantic chunking using percentiles are significantly shorter (both in terms of the number of characters and the number of tokens) than chunks created by semantic double-pass merging chunking.
In this test, no maximum chunk length was set in the double-pass merging algorithm. As a result of tokenization on the created chunks, the sum of tokens in each tested approach turned out to be very similar (except for the proportion-based approach). It’s worth noting the chunks generated by the proposition-based method. The use of the gpt-4 and gpt-4-turbo models results in a significantly longer process time for a single document. As a result of this extended process, the longest chunks are created, but there are relatively few of them in terms of the total number of tokens. This occurs because this approach compresses information by strictly focusing on facts. On the other hand, the propositions-based approach based on gpt-3.5 generates significantly fewer propositions, which then need to be stitched together into complete chunks. As a result, the execution time is much shorter.
The differences in the time required for proposition-based chunking with various models stem from the number of propositions generated by each model. gpt-3.5-turbo created 238 propositions, gpt-4-turbo created 444, and gpt-4 created 361. Propositions generated by gpt-3.5-turbo were also simpler and contained individual facts from multiple domains, making it harder to combine them into coherent chunks, hence the lower average chunk length. Propositions generated by gpt-4-turbo and gpt-4 were more specific and numerous, facilitating the creation of semantically cohesive chunks.
When comparing costs, it’s worth emphasizing that the text used for testing various methods consisted of 75 042 characters. Creating chunks for such a text is possible for free with semantic chunking methods like double-pass (uses spaCy to compute embeddings, and using a different embedding calculation method may increase costs) and classical sentence-based chunking. Methods utilizing embeddings (token-based and semantic percentile-based chunking) incurred costs lower than 0.01 USD. However, significant costs arose with the proposition-based chunking method: the approach using gpt-3.5-turbo costed 0.29 USD. This is nothing compared to generating chunks using gpt-4-turbo and gpt-4, which incurred costs of 17.80 and 29.33 USD, respectively.
| Chunking type | Mean correctness score | Mean relevancy score | Mean faithfulness score | Mean semantic similarity score |
| Token-based | 3,477 | 0,841 | 0,977 | 0,894 |
| Sentence-based | 3,522 | 0,932 | 0,955 | 0,893 |
| Semantic percentile | 3,420 | 0,818 | 0,955 | 0,892 |
| Semantic double-pass merging | 3,682 | 0,818 | 1,000 | 0,905 |
| Propositions-based gpt-3.5-turbo | 2,557 | 0,409 | 0,432 | 0,839 |
| Propositions-based gpt-4-turbo | 3.125 | 0.523 | 0.682 | 0.869 |
| Propositions-based gpt-4 | 3,034 | 0,568 | 0,887 | 0,885 |
We can see that the semantic double-pass merging chunking algorithm achieves the best results for most metrics. Particularly significant is its advantage over classical semantic chunking (semantic percentile) as it represents an enhancement of this algorithm. The most important statistic is the mean correctness score, and it is on this metric that the superiority of the new approach is evident.
Surprisingly, the proposition-based chunking methods achieved worse results than the other methods. RAG based on chunks generated with the help of gpt-3.5-turbo turned out to be very weak in the context of the analyzed text, as seen in the above table. However, RAGs based on chunks created using gpt-4-turbo/gpt-4 proved to be more competitive, but still fell short compared to the other methods. It can be concluded that chunking methods based on propositions are not the best solution for long prose texts.
Summary
Applying different chunking methods to texts with diverse characteristics allows us to draw conclusions about each method’s effectiveness. From the test involving chunking a straightforward text with distinct topic segments, it’s evident that clustering-based chunking is totally unsuitable as it loses sentence order. Classical chunking methods like sentence-based and token-based struggle to properly divide the text when segments on different topics vary in length. Classical semantic chunking performs better but still fails to perfectly chunk the text. Semantic double-pass merging chunking flawlessly handled the simple example.
Chunking a text containing pseudocode focused on comparing semantic chunking methods: percentile-based, double-pass, and proposition-based. Semantic chunking with a breakpoint set by percentiles couldn’t chunk the text optimally for any breakpoint value. Even for values allowing chunking of regular text (i.e., settings like in the first test), the method struggled, creating new chunks in the middle of pseudocode fragments. Semantic double-pass merging and propositions-based chunking using gpt-4 performed admirably, creating thematically coherent chunks.
A test conducted on a long prose text primarily focused on comparing metrics offered by LlamaIndex, revealing statistical differences between methods. Semantic double-pass merging and proposition-based method using gpt-4 generated the longest chunks. The fastest were classical token-based and sentence-based chunking due to their low computational requirements. Next were the two semantic chunking algorithms: percentile-based and double-pass chunking, which took twice as long. Proposition-based chunking took significantly longer, especially when using gpt-4 and gpt-4-turbo. This method, using these models, also incurred significant costs.
The free tested chunking methods were sentence-based and semantic double-pass merging chunking. Nearly cost-free methods were those based on token counting: token-based chunking and semantic percentile-based chunking. Comparing statistical metrics for RAGs created based on chunks generated by the aforementioned methods, semantic double-pass merging chunking performs best in most statistics. It’s notable that double-pass outperformed regular semantic percentile-based chunking as it’s its enhanced version. Classical chunking methods performed averagely, but far-reaching conclusions cannot be drawn about them because the optimal chunk length may vary for each text, drastically altering metric values. Proposition-based chunking is entirely unsuitable for chunking longer prose texts. It statistically performed the worst, taking significantly longer and being considerably more expensive.
All content in this blog is created exclusively by technical experts specializing in Data Consulting, Data Insight, Data Engineering, and Data Science. Our aim is purely educational, providing valuable insights without marketing intent.